Many of the top ad and analytics service providers give their users snippets of code to add to their website, and in many cases the snippet includes a unique identification tag that website owners will use across their domains. Because of this, it’s possible to correlate ownership across domains if you can search the sources of a large amount of websites.
There are 2 main problems with this
- There are a lot (a lot) of advertising and analytics services; very difficult to account for all of them
- Our results will only ever be as good as the data we are querying
Both issues can be greatly aided by HttpArchive, which provides a monthly-updated huge open source dataset of info on millions of websites and also a yearly Web Almanac which breaks down the results of the data.
Using the Web Almanac, we can learn tons of information that can help with the challenges outlined above.
- analytics is the most common third party requested resource by web pages, followed by CDNs (63%) and ads (57%).
What this tells us is that there is definitely potential value to be gained from an approach like this; the vast majority of sites are using analytics (and the slight majority use ads).
Along with the nicely presented graphs, the Web Almanac also links to a spreadsheet with relevant data. Using this, combined with some other datasets, we can pretty easily see which services are the most used, and base the following steps off of that info instead of potentially wasting our time.
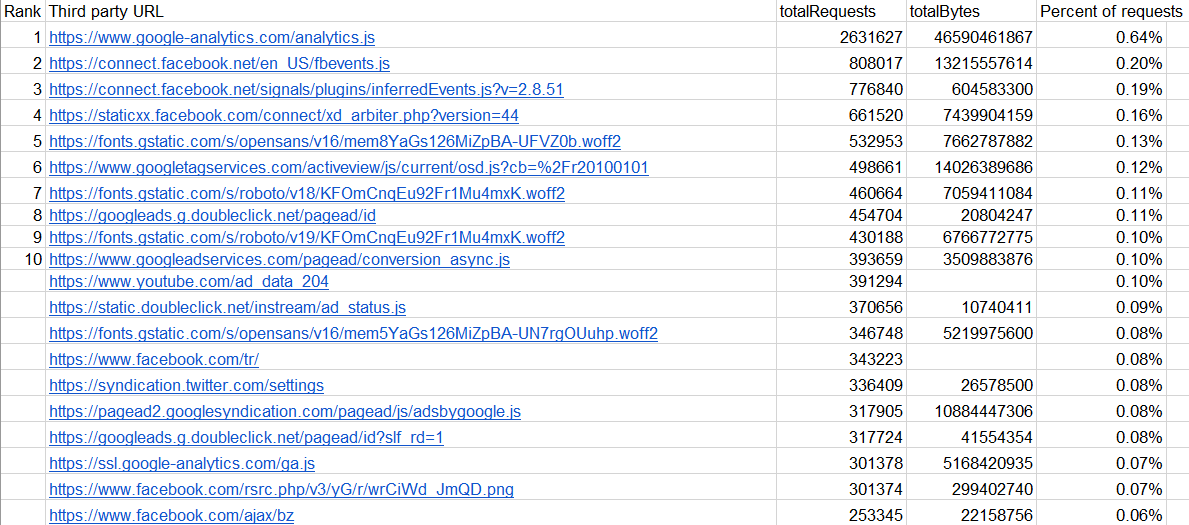

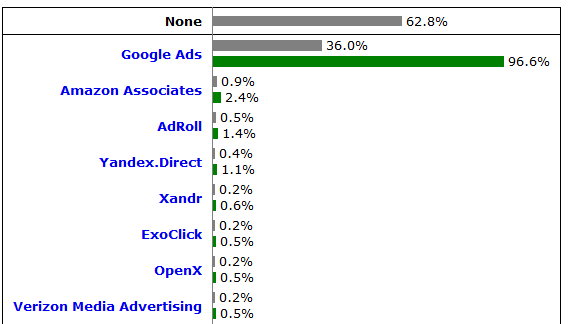

It’s also possible to query HttpArchive’s data with BigQuery, although that can get expensive fast (from using BigQuery, HttpArchive is free), and since I don’t have a ton of money to just throw at random projects I’m going to stick to free solutions :P
The standouts here are pretty clear, and for the most part not particularly surprising.
For analytics our key players are:
-
Google Analytics [AKA Universal Analytics] (monitor website usage):
- ID looks like: UA-x-y
- where x is a string of digits (no fixed length) and y is the property number
- a property is an app/website contained in your analytics account
- where x is a string of digits (no fixed length) and y is the property number
- generally seen with (www.google-analytics.com/) ga.js (legacy), analytics.js (standard) and www.googletagmanager.com/gtag/js?id=GA_MEASUREMENT_ID
- gtag.js (Global Site Tag) is the recommended tracking method by Google now, but many (most) sites have been slow to adopt it. It is used to easily integrate with Google’s other services
- ID looks like: UA-x-y
-
Google Tag Manager (tag management system)
- IDs are generated per container
- containers can contain one or more websites (or apps), meaning that if a user creates multiple containers for different websites, there will also be different IDs
- ID looks like: GTM-X, where X is a string with varied lengths (~4-8) of both letters and numbers
- containers can contain one or more websites (or apps), meaning that if a user creates multiple containers for different websites, there will also be different IDs
- seen with www.googletagmanager.com/gtm.js, and www.googletagmanager.com/ns.html
- IDs are generated per container
-
Facebook Pixel (monitor website usage)
- ID is just a long string of numbers.
- www.facebook.com/tr?id=12345678912345
- fbq(‘init’, ‘1234567891234567’);
- seen with connect.facebook.net/en_US/fbevents.js and http://www.facebook.com/tr?id=ID
- Also used to track conversions
- Generally people will not use the same pixel across multiple sites, so it may not be useful in this case.
- ID is just a long string of numbers.
-
Yandex.Metrika (website analytics)
- Primarily used in Russia
- id can be found with
/mc.yandex.ru/watch/ZZZZZZZZwhere Z is a digit - seen with mc.yandex.ru/metrika/watch.js
-
etc.
For Ads:
-
Google AdSense (serve ads to a website)
- ID looks like: pub-1234567891234567 or ca-pub-1234567891234567 (where ca is the product specific prefix) (16 digits)
- generally seen with pagead2.googlesyndication.com/pagead/js/adsbygoogle.js
- there is also Google Ad manager (previously doubleclick for publishers) which just allows you to manage ads on various networks but uses the same id associated with your adsense account
-
Google Ads [Previously known as AdWords] (ad conversion tracking)
- ID looks like: AW-x where x is a string of digits with varying length
- It is uncommon for this to be used across multiple domains.
- because of this, I don’t consider it to be particularly useful for the purposes of this post, although it may be worth trying in some cases.
-
Facebook Ads (essentially Facebook Pixel for our purposes)
-
etc.
Step 1 Complete
find services that we can track across domains- get other domains from the ids we found
Phew. Alright, that’s one of the two challenges solved. For the second, luckily, there’s plenty of sites that index the source code of websites, some even specifically checking for analytics/advertiser tags.
- http://spyonweb.com/
- https://host.io/
- https://publicwww.com/
- https://www.nerdydata.com/
- google dorking
Aside from analytics and ads, there are a ton of other fields which use a similar id system that we’ve seen above (Amazon Affiliate link, AddThis ids, etc.) Even a unique copyright string may be enough in some cases.
It should be noted that 2 sites sharing an id is not alone enough to assume they are 100% owned by the same organization/individual, but rather something to branch other searches off of.
Let’s try it out!
What better place to try this out on than a far-right opinion/news website? The Gateway Pundit, known for being much less than truthful in its news reporting, is going to be our starting point. I’ll show how this can be automated later, but for now the searching will be manual.
First looking at the website, it looks like your traditional clickbait at best (straight lies at worst) news source
Looking at the source of the page, I’m just going to CTRL-F (browser find tool) to look for the common analytics or ad ID formats.
As of June 1st, 2020, there is:
- UA-54260989-7 (Google Analytics)
- GTM-K3K9VP (Google Tag Manager)
I also noticed that the cloudfront (cdn) distribution domain http://d3l320urli0p1u.cloudfront.net/script.js is used, which has a seemingly obfuscated source and was blocked by my adblocker.
Using some of the free tools I mentioned earlier, we can check out other sites that have these IDs.
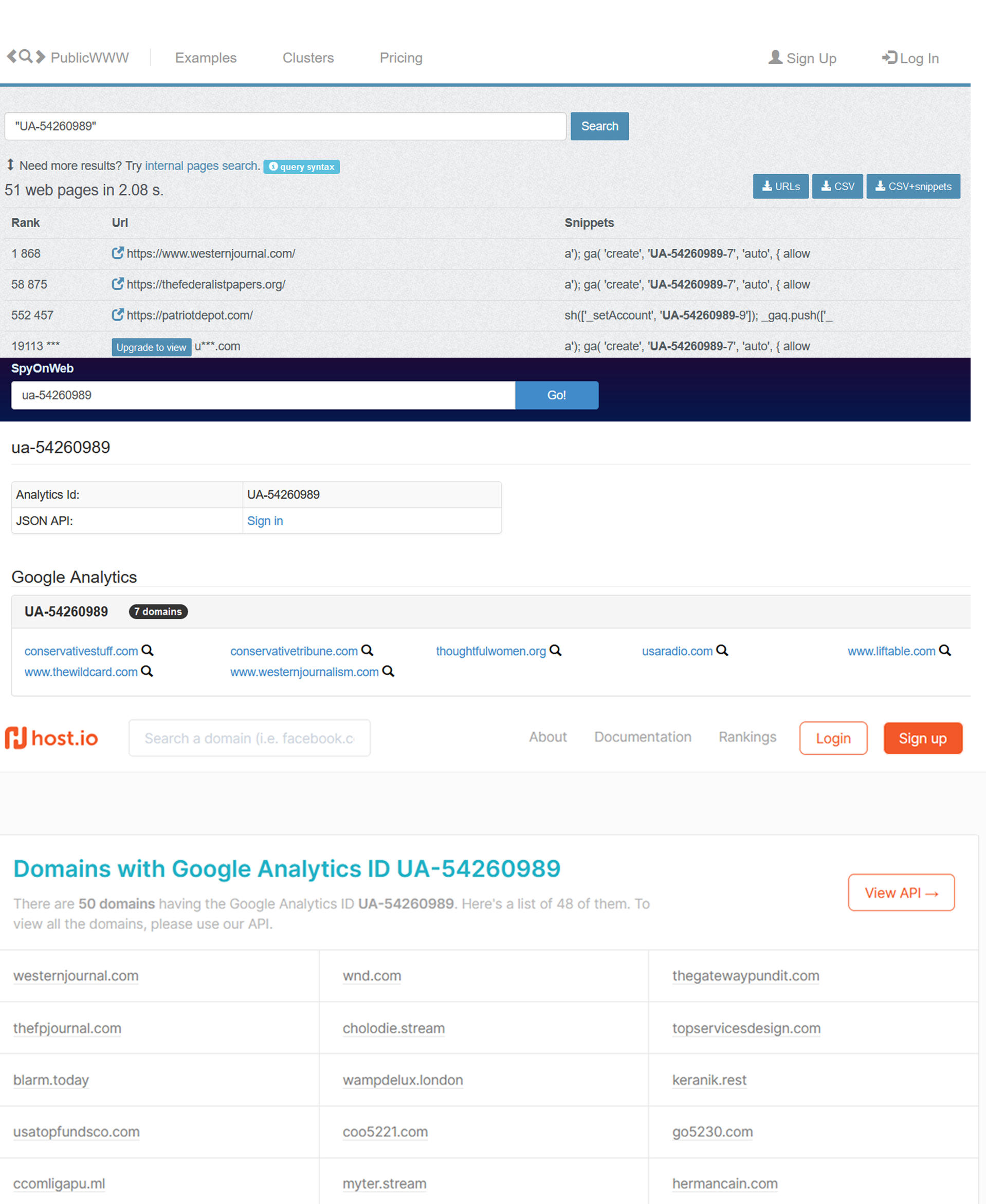
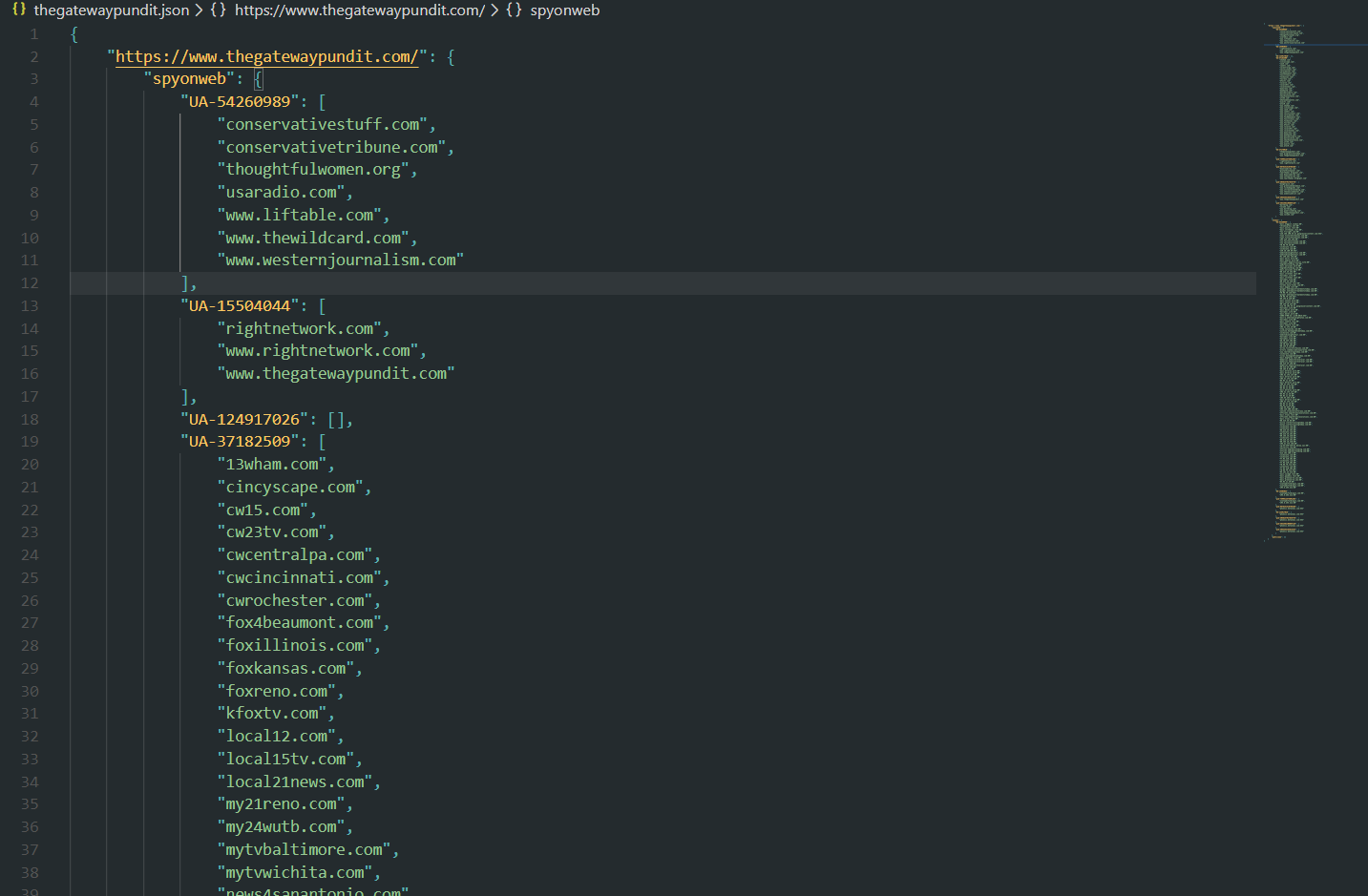
Google Analytics Results
And with the Google Tag Manager ID:
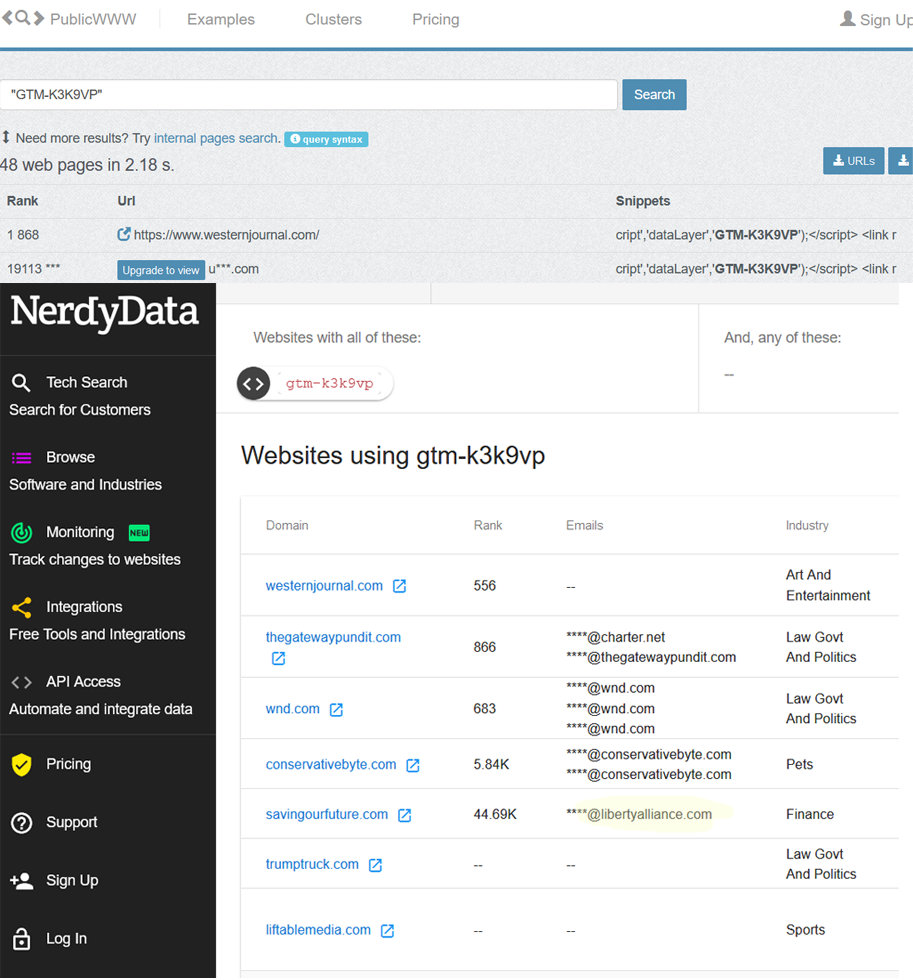
Google Tag Manager Results, keep that @libertyalliance.com email address in the back of your mind!
find services that we can track across domainsget other domains from the ids we found
There’s obviously a ton of sites here, so let’s look at the results given by publicwww as it sorts by Alexa Rank (site popularity).
-
westernjournal.com
- using
d3l320urli0p1u.cloudfront.net/script.js - verified to have
UA-54260989 - verified to have
GTM-K3K9VP - using quantcast:
p-s4EjFfr0LYkYa
- using
-
thefederalistpapers.org
- using
d3l320urli0p1u.cloudfront.net/script.js - verified to have
UA-54260989 - has GTM ID:
GTM-P9WV2KG - using facebook pixel:
126343467805147 - using quantcast:
p-GPQDLS2Cn0Nhm,p-s4EjFfr0LYkYa
- using
-
patriotdepot.com
- verified to have
UA-54260989 - using quantcast:
p-kZpd2WPpvPttS - using facebook pixel:
606809489393836 - Previously using
GTM-P7X9K7, changed to using:GTM-5FDBP7Lby [Name]
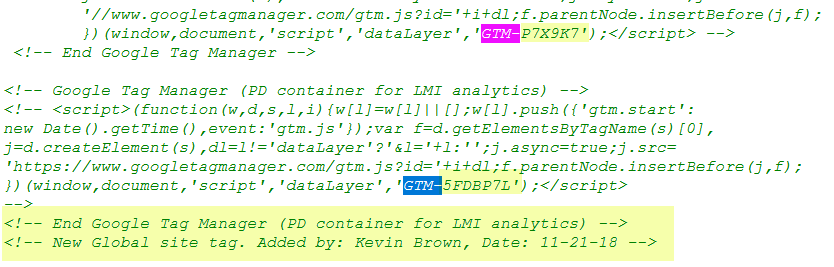
We’ll look into what ‘LMI’ means later
- verified to have
To break this down, here are the important parts:
- 4/4 sites use the same google analytics id
- 3/4 sites use the same cloudfront distribution domain
- 2/4 sites use the same google tag manager id
- 2/4 sites use the same quantcast publisher id
Additionally, only patriotdepot.com is not using the firefly wordpress theme out of the 4 sites.

thegatewaypundit.com, westernjournal.com, thefederalistpapers.org, patriotdepot.com
The sites are clearly related somehow, but how? A search about relationships between any 2 domains results in mainly just talks of conservative websites (which all of these happen to be) and domain lists.
A quick search about westernjournal will show that it’s owned by “Liftable Media Inc”, and in the copyright footer for patriotdepot, this name is repeated:

This is most likely the “LMI” that [Name] was referring to in his html comment. If you search “[Name] Liftable Media” you’ll also find the linkedin for [Name], the Liftable Media Web Developer. liftablemedia.com also has the same GTM ID as westernjournal.com and thegatewaypundit.com: GTM-K3K9VP.
So how does “Liftable Media Inc.” connect the other sites to patriotdepot and westernjournal?
Western Journal was acquired by Liftable Media in 2015, Tea Party News Network in 2016, and then later in 2017 Liftable media went on to absorb some of the assets owned by Liberty Alliance, a group founded by Brandon Vallorani of ~100 conservative news sites, and generally regarded as a questionable source at the very least. Patriot Depot was acquired by Liftable Media about a month after the Liberty Alliance acquisition.
libertyalliance.com, although no longer live, can be accessed via webarchive, and has posts linking to westernjournal articles from 2018.
Looking at the company leadership section of Liberty Alliance’s wikipedia page, “Ted Slater” is credited for website development. And on his Linkedin, he has a project that’s been going since 2014 called “Patriot Ad Network”, which is an ad management service for publishers who are targeting a “conservative and christian audience”.

Patriot Ads claims to manage some of the most high traffic sites in America. Looking at Ted’s site linked on LinkedIn, he also claims to have worked on The Gateway Pundit, “and many others”.
The picture is becoming more clear. Liftable Media, the owners of The Western Journal (previously Western Journalism) as of 2015, acquired a large amount of additional conservative websites in 2016-17 and most likely used Patriot Ads, a service created by individuals involved with Liberty Alliance, to help organize and increase their monetization capabilities, which was done partly using Google Analytics and Tag Manager. The Gateway Pundit and The Federalist Papers, among many others, were members of one of the networks acquired by Liftable Media Inc.
Interestingly, the only brand Liftable Media seems to actively associate with is The Western Journal (and to a lesser extent Patriot Depot), although it is clear they own massive amounts of far right-leaning news sites.
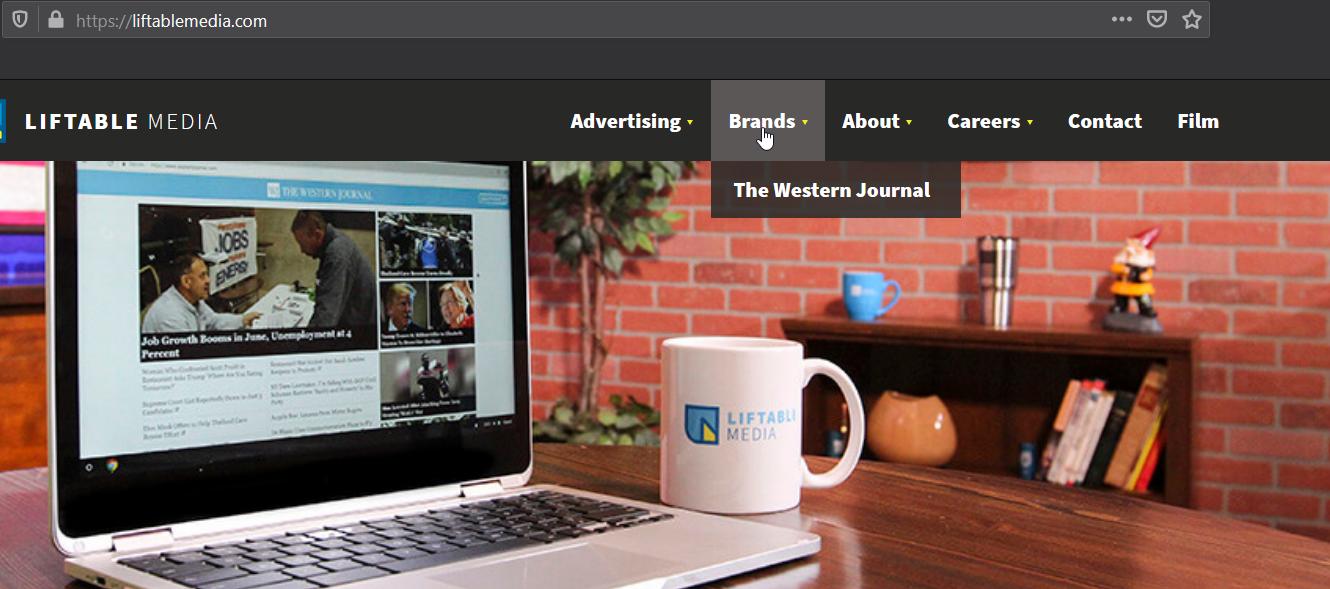
The acquisition of Liberty Alliance, Tea Party News, or other large networks is not even mentioned in the “Our Story” section, while Patriot Depot is.
Automation
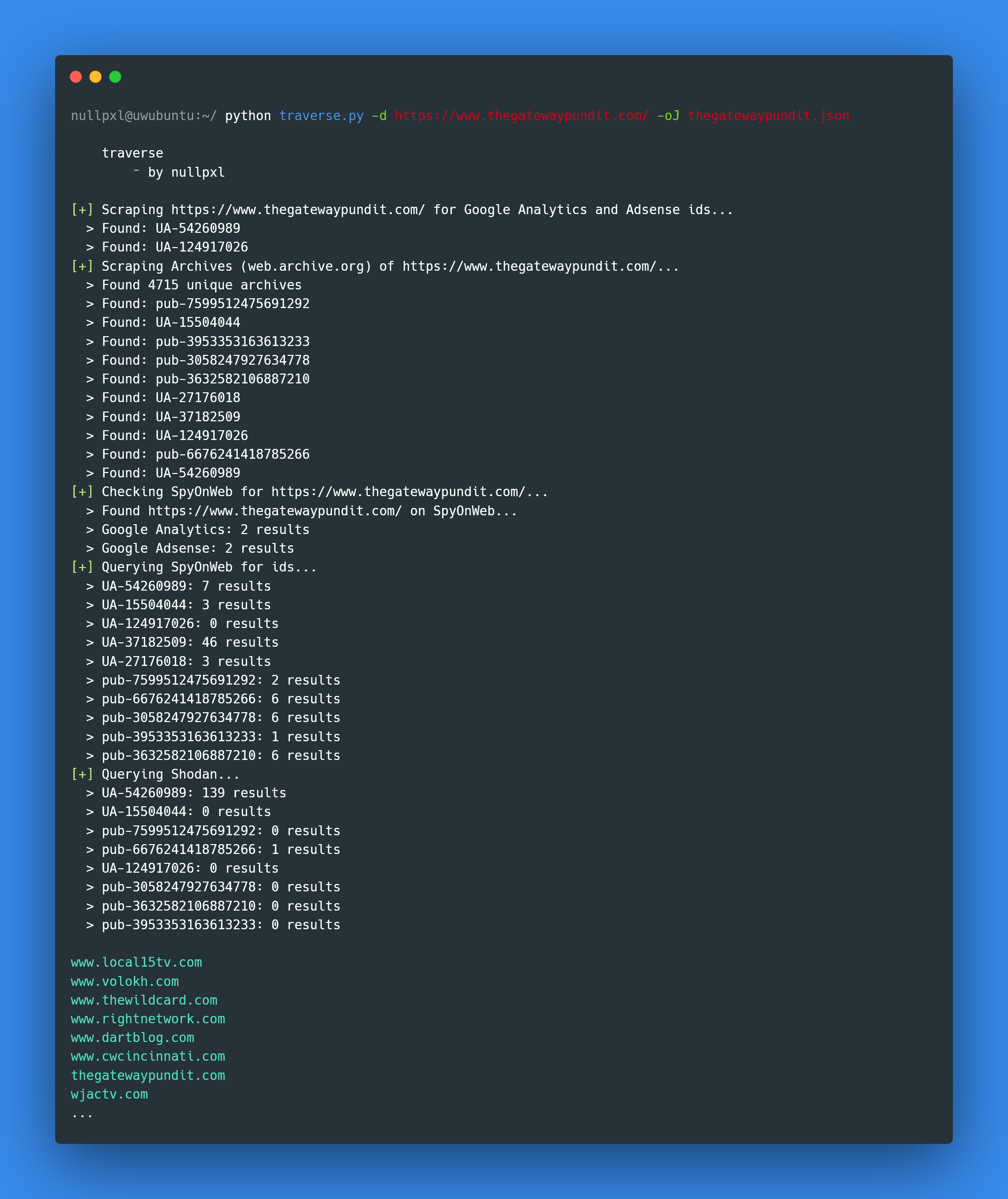
The phrase “If you have a repetitive task, automate it” definitely holds up in this case. Fortunately, most of the services used in the previous sections have pretty decent free apis. It’s also fairly simple to use regex to look for id types in the sources of both live and archived versions of pages.
I’ve implemented much of this in my open source tool Traverse, which is still being updated with different ID types and the ability to interact with the apis of more services.
https://github.com/NullPxl/traverse
If you’ve got any other ideas relating to this topic, or about traverse, let me know!