In blog posts and courses on Open Source Intelligence (OSINT) there's often a section to convey the importance of archiving everything you come across. If something related to your research gets deleted / altered somehow, it's good to have a backup of sorts. Probably the most well-known and circulated website archiving tool is the Internet Archive's WayBack Machine.
The WayBack Machine is a very common tool for investigative journalists. The Global Investigative Journalism Network even has a blog post about it.
Something I haven't seen mentioned before is the fact that the use of archiving tools such as the WayBack machine can inadvertently alert the website owner that they are potentially being observed. This could pose a problem for ongoing investigations.
For example, imagine you are doing research on an extremist group and come across a user's personal website in a Telegram channel. The initial instinct might be to save the current state of the page with the WayBack machine. However, a technically proficient user may be monitoring access logs for their website.

In the above screenshot, I am looking at the access logs for a website that I control. With no additional tooling other than the nginx (a popular web server) defaults, I can view the IP address of visitors as well as their User Agent and other request information. Things like the IP address, User Agent, and even order of requests could be used to ‘fingerprint’ requests coming from the WayBack machine. From the IP address present in the screenshot, I can easily check the organization which has control of it.
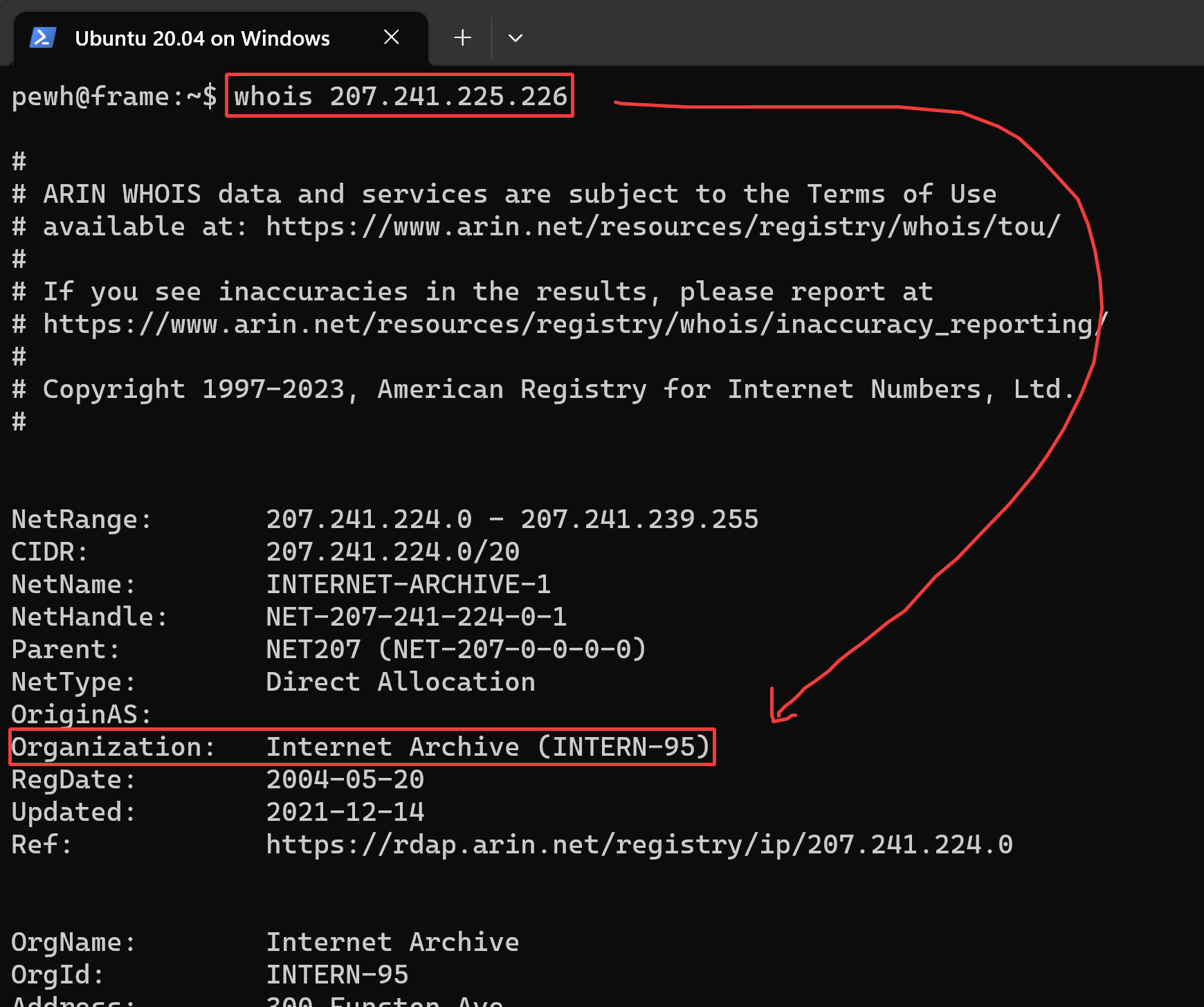
Once the user sees this, they may tell the rest of the Telegram channel and move communications to a platform you are not monitoring. If I wanted to go further, I could set alerts for all IP addresses controlled by the Internet Archive, which is simple to find.
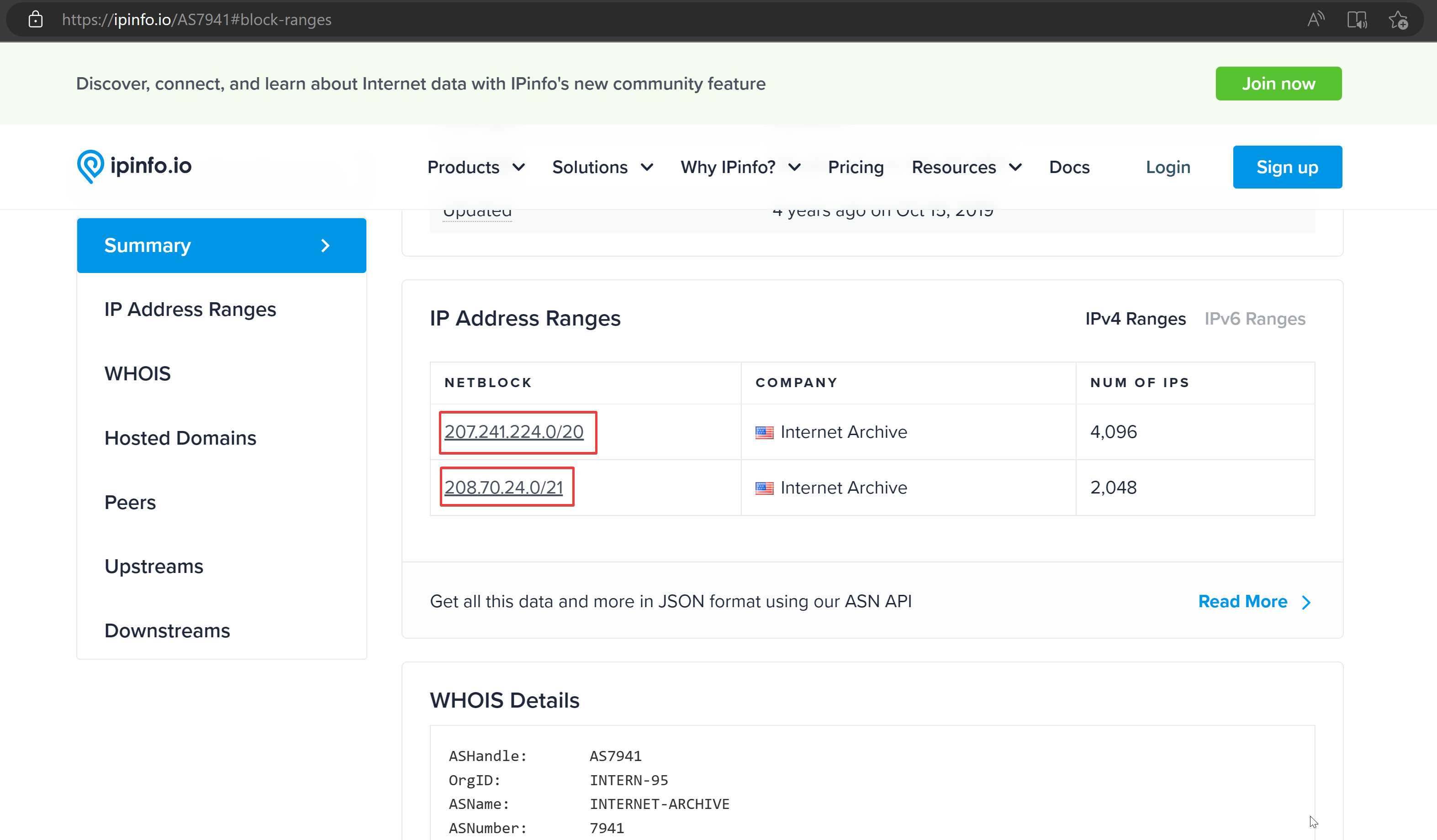
In a more likely scenario, anyone who knows about the website could check public web archives like the WayBack Machine for snapshots. This can also be achieved programmatically. In this sense, archiving with public tools could act as a canary.
I'm not saying that you shouldn't archive websites you come across– you definitely should. Rather, I'm saying that before using public and popular archiving tools, consider a few things:
- Is the website owner likely to be technically proficient?
- Is the investigation ongoing, and will the website owner being alerted of observation create potential issues?
Regardless of the above, you should always download pages locally and take screenshots. This is not nearly as good as having a copy on the WayBack Machine, but it is better than nothing.
Ideally, a web archive tool would exist that can be used in active investigations without worry. The main value of website archives comes from their reputation and trust. While the Internet Archive's WayBack Machine has been successfully used as evidence in court before (although not without struggle), any tool that I would create would start with absolutely 0 trust behind it. That said, I would not expect the Internet Archive to implement a ‘private archive’ tool as it goes against their core tenet of free and publicly available information.
So we're left with fulfilling the following requirements:
- Built by an extremely trustworthy organization with enough funding to keep the service going indefinitely
- Potentially Mozilla or some long-standing journalism organization?
- Extremely difficult to fingerprint
- IP rotation is probably necessary, but would cost a decent amount of money to continuously be using new IPs/proxies that people haven't noted down.
- Randomize choice of User-Agent from list of various popular browsers and devices (do this type of randomization for every request variable you can think of)
- Randomized order of requests (don't always do index.html, then styles.css, then favicon.ico, etc.)
- Don't load javascript unless necessary
- Archives can not be public
- Otherwise, the website owner could check / scrape the archive site at various intervals to see if there are new snapshots taken.
- Should require some form of password. The password could be a hash of the html content of the page for example.
Please let me know if you have other ideas! (contact)